Integração Contínua
Em uma equipe com vários desenvolvedores, todos trabalhando na elaboração de um mesmo sistema, qual a melhor forma de unificar as diversas alterações feitas na base de código? Processos ágeis como o xp utilizam a prática conhecida como Integração Contínua para solucionar essa questão.
Integração contínua consiste em integrar o trabalho diversas vezes ao dia, assegurando que a base de código permaneça consistente ao final de cada integração. Nesse artigo, você conhecerá os passos necessários para usar essa prática em seu dia-a-dia, primeiro de forma manual, com foco nos conceitos, e depois de forma automatizada.
Repositórios e versionamento
Uma das ações mais importantes para permitir que diversos desenvolvedores trabalhem juntos em um mesmo projeto é utilizar um sistema de controle de versões, que chamaremos aqui de "repositório de código" ou simplesmente "repositório". Existem muitos desses sistemas disponíveis no mercado, tais como CVS, Microsoft Visual SourceSafe, Subversion, Rational ClearCase, entre outros. Nesse artigo iremos utilizar o CVS para apoiar nosso exemplo. Trata-se de um software open source amplamente utilizado em todo o mundo.
Repositórios de código fornecem um local centralizado para armazenamento dos arquivos de um projeto, e também controlam as versões desses arquivos. Imagine, por exemplo, que num projeto haja uma classe CestaCompras com capacidade apenas de listar e calcular o valor total dos produtos na cesta, e que um dia alguém implemente também a inserção e a remoção de produtos. Ao armazenar o código atualizado com as novas funcionalidades, o repositório grava uma nova versão da cesta. Ou seja, a classe CestaCompras original não é simplesmente substituída por uma nova. Ao invés disso, o novo código é anexado ao antigo.
Guardar versões é como ter um botão de "desfazer" à nossa disposição. Quando cometemos um erro em um arquivo e o colocamos acidentalmente no repositório, o repositório nos permite recuperar a versão anterior. No caso da classe CestaCompras, por exemplo, imagine que a primeira versão funcionasse perfeitamente e, ao implementarmos a inserção e remoção de produtos, tivéssemos inserido um bug por falta de atenção. Suponha ainda que o bug só fosse percebido quando a classe já estivesse em produção. Nesse tipo de situação, a possibilidade de controlar versões com um repositório de código é muito útil, por exemplo, porque nos permite obter a versão original rapidamente (a que funcionava) e colocá-la no ar até que a versão mais recente (com problemas) seja corrigida.
Quando diversas pessoas trabalham juntas em um projeto, o repositório se torna o destino final de tudo o que é produzido. Quando um desenvolvedor armazena seu trabalho no repositório, dizemos que está fazendo uma integração, isto é, está integrando o que acabou de produzir com o que seus colegas também vêm produzindo e armazenando no repositório.
Formas de integração
Em um projeto, com várias pessoas trabalhando juntas, é comum acontecerem situações nas quais dois ou mais desenvolvedores precisem editar determinado arquivo ao mesmo tempo. Como tratar essa possibilidade?
Existem duas abordagens utilizadas. Na mais simples, o primeiro desenvolvedor que precisa editar um arquivo faz um checkout desse arquivo e, enquanto o estiver editando ninguém mais consegue alterá-lo. Ou seja, o arquivo passa a ter apenas acesso de leitura para todos os outros desenvolvedores. (Fazer um checkout significa trazer uma cópia de um ou mais arquivos do repositório para a estação de trabalho do desenvolvedor.) Usa-se esse modelo de edição de arquivos em sistemas como o Microsoft Visual SourceSafe, por exemplo.
A outra abordagem, que iremos tratar com mais detalhes ao longo do artigo, é adotada freqüentemente por usuários do CVS e do Subversion, por exemplo. Nela, cada desenvolvedor faz checkout de todo o projeto para a sua máquina, e tem liberdade para editar qualquer arquivo sem ter que se preocupar se outras pessoas também estarão editando o mesmo arquivo que ele.
Quando termina sua tarefa, o desenvolvedor pede ao CVS para integrar seu código ao repositório. Para cada arquivo que alterou, o CVS verifica se outra pessoa também fez alterações. Quando isso ocorre, torna-se necessário fazer um merge, isto é, unificar as alterações dos diferentes desenvolvedores.
O merge pode ser automático ou manual. O merge automático ocorre quando o CVS detecta que duas pessoas editaram o mesmo arquivo, porém constata que linhas diferentes foram alteradas. Nesse caso, o CVS simplesmente aceita as duas (ou mais) alterações no arquivo. Já quando dois programadores editam a mesma linha de código, torna-se necessário fazer um merge manual. Então, o CVS marca no código o trecho em que existe o conflito e o programador tem que analisar manualmente as mudanças e decidir como os códigos devem ser unificados.
O modelo de trabalho do CVS traz uma série de vantagens, mas parece mais arriscado que aquele em que desenvolvedores editam arquivos com exclusividade sobre os mesmos. Entretanto, utilizando as recomendações que veremos adiante, você poderá utilizá-lo de forma segura. Assim poderá editar arquivos livremente, sabendo que na hora de integrar não irá causar nenhum mal aos arquivos já presentes no repositório.
Integração através de um exemplo
Para que você possa experimentar o processo de integração, iremos ajudá-lo a simular o que aconteceria em um pequeno projeto, cujo objetivo é criar uma calculadora usando práticas do xp. Sendo assim, além da integração contínua, outras práticas serão usadas, tais como programação em par e desenvolvimento orientado a testes, mas não é necessário conhecer detalhes sobre essas técnicas para acompanhar o artigo.
Nesse exemplo, iremos considerar uma equipe composta por quatro desenvolvedores: Ana, Bruno, Carlos, e Denise. Eles irão trabalhar em pares, e usarão dois computadores diferentes. Em um computador, Ana e Bruno irão trabalhar juntos, enquanto no outro estarão Carlos e Denise. O Eclipse será utilizado no projeto.
Para simular as condições exatas desse projeto, será necessário criar em seu computador dois workspaces, um para cada par. No meu computador, por exemplo, criei os seguintes diretórios:
/Users/vinicius/workspaceAB (para o par Ana e Bruno) /Users/vinicius/workspaceCD (para o par Carlos e Denise)
Você também deverá ser capaz de abrir duas cópias diferentes do Eclipse, de modo que possa alterar o conteúdo de cada workspace, à medida que avançarmos na explicação. Uma forma simples de fazer isso é instalar o Eclipse em dois diretórios diferentes. No meu caso, por exemplo, ele foi instalado nos seguintes diretórios:
/Users/vinicius/eclipseAB /Users/vinicius/eclipseCD
Finalmente, você precisará ter acesso a um servidor CVS. Se estiver em um ambiente administrado, onde já exista um CVS instalado, peça acesso ao responsável pela infra-estrutura. Caso contrário, você poderá baixar e instalar o CVS a partir dos links fornecidos ao final do artigo. Explicar como instalar o CVS está fora do escopo desse artigo, mas os links e livros sugeridos serão úteis nesse sentido.
Iniciando o exemplo
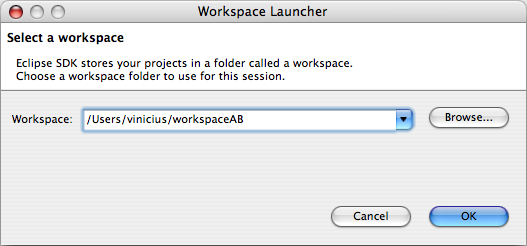
Iremos começar simulando o par Ana e Bruno. Para isso, execute o Eclipse reservado para eles. Em seguida, configure-o para utilizar o workspace destinado a esse par, através da opção File|Switch Workspace. Veja a Figura 1.
Figura 1: Configurando o workspace do Eclipse para o primeiro par.
Criando o projeto e os diretórios
Crie um novo projeto Java chamado Calculadora e configure os diretórios onde serão armazenados os códigos fontes. Haverá dois diretórios, um para o código da aplicação (src) e outro para os testes (srcTeste). Para efetuar a configuração, escolha Project|Properties, clique na opção Java Build Path no painel à esquerda e depois na aba Source à direita. Depois clique no botão Add Folder, digite src e clique em Ok.
Nesse momento o Eclipse irá perguntar se você deseja direcionar os arquivos compilados para o diretório bin. Aceite essa sugestão. Agora só falta adicionar o diretório srcTeste. Para isso, clique novamente no botão Add Folder e em seguida no botão Create New Folder e digite srcTeste. Com isso, os diretórios onde serão armazenados os fontes estão configurados.
Configurando o JUnit
Para executar testes automatizados, usaremos o JUnit. Para isso, é necessário adicionar a biblioteca junit.jar no classpath do projeto. Existem pelo menos duas formas de se fazer isso. A primeira é configurar o projeto para referenciar junit.jar no diretório do plug-in do JUnit que já vem com o Eclipse. A outra é criar um diretório lib no projeto, copiar o junit.jar para esse diretório, e configurar o projeto para usá-lo.
Usaremos a segunda opção porque, mais tarde, ao colocar o projeto no repositório, queremos que ele seja armazenado com todos os arquivos e bibliotecas dos quais depende, incluindo a biblioteca do JUnit.
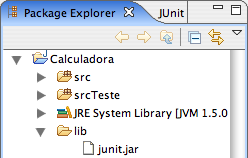
Crie um diretório chamado lib (File|New>Folder). Copie o arquivo junit.jar para esse diretório. Você poderá encontrar esse jar no diretório de instalação do Eclipse, no subdiretório plugins/org.junit_3.8.1 (a versão pode variar). Feita a cópia, escolha a opção de menu File|Refresh. A partir desse ponto, você será capaz de observar a estrutura de diretórios da Figura 2.
Figura 2: Estrutura inicial do projeto.
Para configurar o classpath, selecione o projeto e escolha Project|Properties, clique em Java Build Path e depois na aba Libraries. Depois clique no botão Add JARs e escolha junit.jar.
Primeiras classes
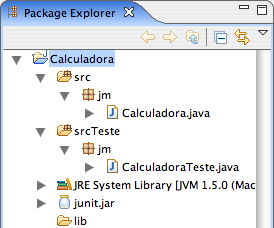
Agora, vamos supor que depois de alguns minutos trabalhando, Ana e Bruno produziram as classes apresentadas na Listagem 1. Ao escrevê-las no Eclipse, note que a classe CalculadoraTeste deve ser colocada no srcTeste, enquanto a classe Calculadora ficará no src. Veja a Figura 3.
Listagem 1: Primeira versão da classe Calculadora e seu teste.
package jm;
import junit.framework.TestCase;
public class CalculadoraTeste extends TestCase {
Calculadora calculadora = new Calculadora();
public void testSoma() {
assertEquals(3, calculadora.soma(1, 2));
}
public void testSubtracao() {
assertEquals(1, calculadora.subtrai(3, 2));
}
public void testDivisao() {
assertEquals(2, calculadora.divide(2, 1));
}
public void testMultiplicao() {
assertEquals(2, calculadora.multiplica(1, 2));
}
}
Figura 3: Estrutura do projeto após adicionar as primeiras classes.
Importando o projeto no CVS
Para que os pares possam integrar o que produzem usando o CVS é necessário importar o projeto no CVS, isto é, adicionar os primeiros arquivos do projeto no repositório. Começamos configurando o Eclipse para acessar o repositório.
Figura 4: Configurando o acesso ao repositório.
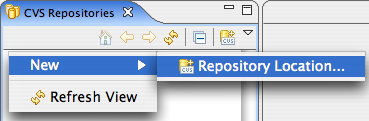
Figura 5: Definindo parâmetros de configuração para o acesso ao CVS.
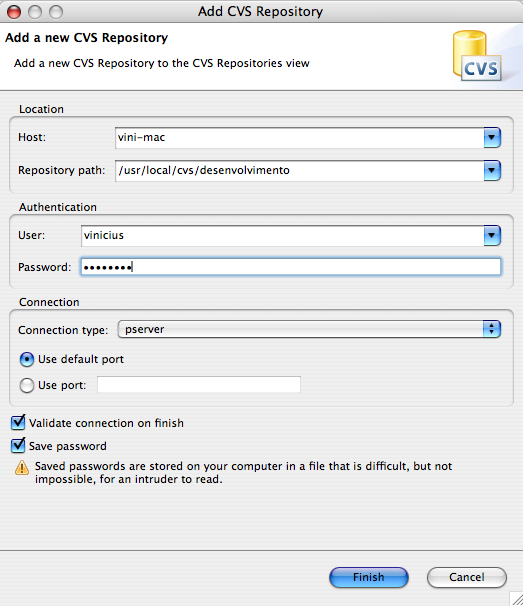
Acesse a opção de menu Window|Open Perspective>Other>CVS Repository Exploring. Clique com o botão direito sobre a perspectiva CVS Repositories e escolha New>Repository Location. Veja a Figura 4. Agora digite os dados relativos à configuração do seu servidor CVS. Veja na Figura 5 como ficou a configuração no meu caso.
Agora que o Eclipse reconhece o repositório, você pode importar o projeto. Volte para a perspectiva Java, clique com o botão direito sobre o topo da estrutura do projeto e escolha a opção Team>Share Project. Desse ponto em diante, selecione as opções padrões oferecidas pelas telas do wizard, conforme ilustrado na Figura 6.
Figura 6: Importando o projeto para o CVS.
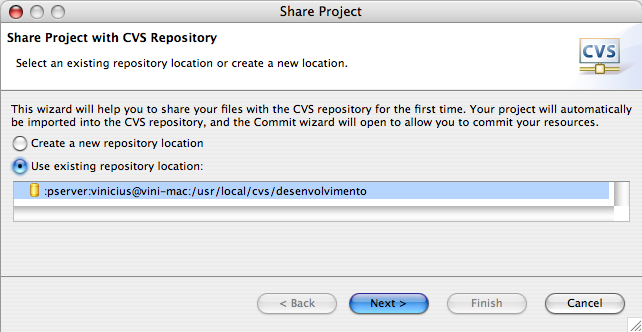
Escolhendo o repositório para onde o projeto será importado.
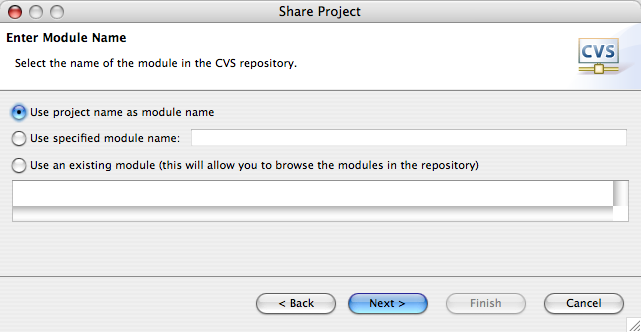
Definindo o nome do módulo no CVS, isto é, como o projeto será conhecido no CVS.
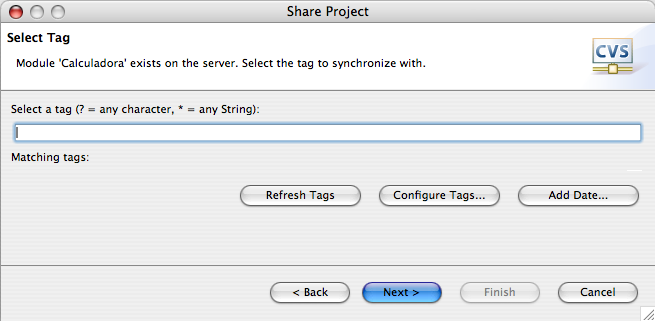
Definindo a tag inicial do projeto. Pode ser vazia.
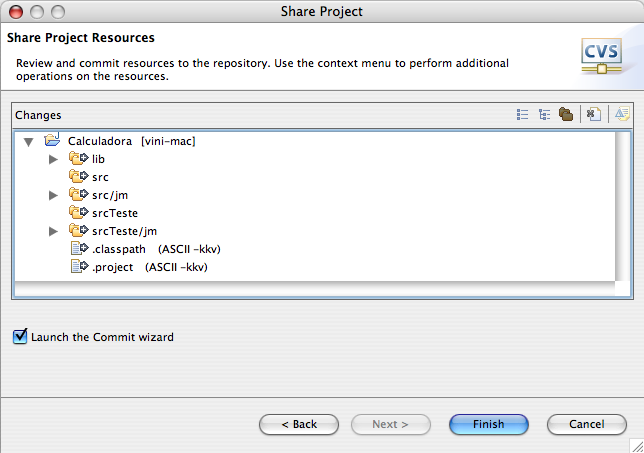
Verificando os arquivos que serão importados e finalizando.
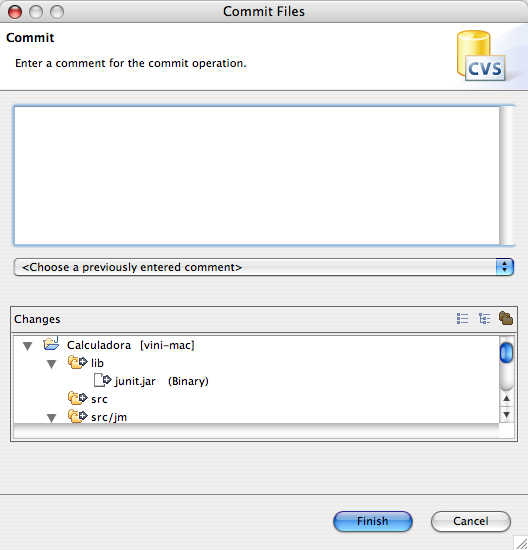
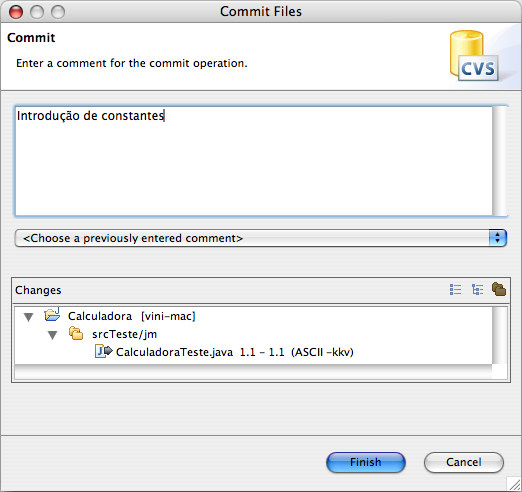
Adicionando um comentário ao gravar os arquivos no repositório.
Sempre que armazenamos novos arquivos ou alterações de arquivos no CVS, ele sugere a inserção de comentários, descrevendo o que está sendo armazenado, o porquê das mudanças etc. A necessidade desses comentários depende das características de cada projeto, como veremos adiante.
Checkout do projeto
Agora que o projeto já está no CVS, vamos imaginar que o outro par, formado por Carlos e Denise, comece a contribuir com o projeto. Para isso, é necessário que eles configurem o Eclipse para acessar o repositório e façam o checkout de todos os arquivos do projeto até o momento.
Para que você possa simular essa situação, execute a instalação do Eclipse que foi destinada para esse segundo par. Em seguida, configure o IDE para usar o workspace de Carlos e Denise, acionando File|Switch Workspace, e digitando a sua localização (no meu caso, /Users/vinicius/workspaceCD).
Acesse Window|Open Perspective>Other>CVS Repository Exploring, e clique com o botão direito sobre a perspectiva CVS Repositories. Depois escolha New>Repository Location. Digite os mesmos dados de configuração do repositório que usamos anteriormente para configurar o workspace do primeiro par.
Nesse momento você já pode fazer checkout do projeto. Na perspectiva CVS Repositories expanda a linha correspondente ao repositório onde está nosso projeto. Você deverá ver algo parecido com a Figura 7.
Figura 7: Acessando o CVS para fazer checkout do projeto.
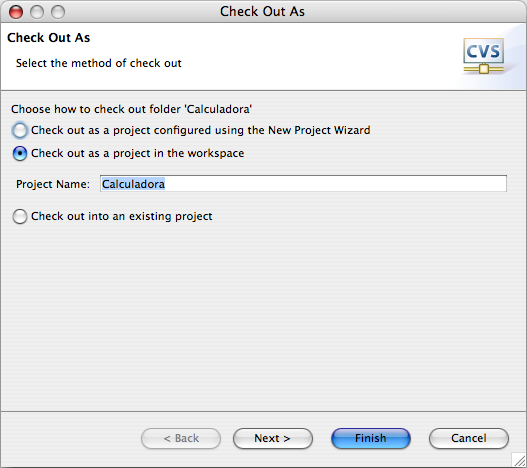
Clique com o botão direito sobre o projeto e escolha a opção Check Out As. Depois escolha Check out as project in the workspace, como ilustrado na Figura 8. Por fim, mude para a perspectiva Java, onde você encontrará os arquivos do projeto.
Figura 8: Definindo a forma de realizar o checkout.
Pares programando em paralelo
Nesse momento, os dois pares estão com a versão original dos arquivos em seus respectivos workspaces. Iremos simular agora uma situação em que cada par altera um arquivo diferente do outro.
Ana e Bruno decidem refatorar a classe de teste com o objetivo de eliminar algumas duplicações. Farão isso acrescentando algumas constantes, conforme o código apresentado na Listagem 2. Por sua vez, Carlos e Denise refatoram a implementação da classe Calculadora com o objetivo de melhorar os nomes dos parâmetros usados nos métodos. O resultado é apresentado na Listagem 3.
Listagem 2: Ana e Bruno introduzem constantes na classe CalculadoraTeste.
package jm;
import junit.framework.TestCase;
public class CalculadoraTeste extends TestCase {
public static final int UM = 1;
public static final int DOIS = 2;
private static final int TRES = 3;
Calculadora calculadora = new Calculadora();
public void testSoma() {
assertEquals(TRES, calculadora.soma(UM, DOIS));
}
public void testSubtracao() {
assertEquals(UM, calculadora.subtrai(TRES, DOIS));
}
public void testDivisao() {
assertEquals(DOIS, calculadora.divide(DOIS, UM));
}
public void testMultiplicao() {
assertEquals(DOIS, calculadora.multiplica(UM, DOIS));
}
}
Listagem 3: Carlos e Denise melhoram os nomes dos métodos da classe Calculadora.
package jm;
public class Calculadora {
public int soma(int somando, int outroSomando) {
return somando + outroSomando;
}
public int subtrai(int minuendo, int subtraendo) {
return minuendo - subtraendo;
}
public int divide(int dividendo, int divisor) {
return dividendo/ divisor;
}
public int multiplica(int multiplicando, int multiplicador) {
return multiplicando * multiplicador;
}
}
Sincronizando com o repositório
Nesse ponto, cada par terá contribuído de alguma forma com o projeto. Supondo que eles não tivessem mais nada a fazer com relação à calculadora, seria recomendável integrar suas alterações ao repositório. Desenvolvedores que trabalham com xp procuram integrar o que produzem inúmeras vezes ao dia, razão pela qual essa prática é chamada de integração contínua. Toda vez que o código está consistente, ou seja, quando todo o projeto compila e todos os testes automatizados executam perfeitamente, pode-se efetuar uma integração.
Integrar com freqüência significa fazer algumas pequenas alterações no código, assegurar a consistência do mesmo – e também verificar se a base de código guardada no repositório, uma vez acrescida dessas pequenas alterações, continuará funcionando corretamente. Fazer pequenas mudanças e validá-las várias vezes ao dia é vantajoso. Se integramos um pouco de cada vez, o esforço é menor, o potencial de erros diminui e eventuais erros podem ser tratados mais facilmente. Sobretudo, ao final de cada integração, buscamos assegurar que o repositório continue consistente, para que integrações futuras não sejam afetadas negativamente por eventuais erros da integração corrente.
Voltando ao Eclipse, a forma mais simples de integrar alterações nele é pedindo que o código local seja sincronizado com o repositório. Para fazer isso, no workspace de Ana e Bruno, clique com o botão direito na raiz do projeto e escolha a opção Team>Synchronize with Repository. Nesse ponto, pode ser que o Eclipse avise que a ação está associada à perspectiva Synchronize, conforme a Figura 9. Se for o caso, será perguntado se você aceita mudar para essa perspectiva. Responda que sim e prossiga.
Figura 9: Configurando o Eclipse para abrir a perspectiva correta durante a sincronização.
O Eclipse mostra que a única diferença entre o projeto em sua estação e o que está no repositório é a modificação feita na classe CalculadoraTeste que agora deverá ser gravada no CVS. Clique com o botão direito sobre a raiz do projeto e escolha Commit. Veja as Figuras 10 e 11.
Figura 10: Resultado da sincronização. Modificações locais na classe CalculadoraTeste.
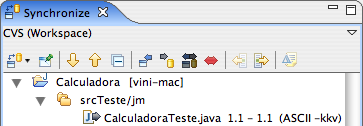
Figura 11: Adicionando um comentário descrevendo a alteração efetuada.
Roteiro da integração contínua
Agora que Ana e Bruno integraram sua contribuição, é a vez de Carlos e Denise fazerem o mesmo. Mas dessa vez eles seguirão o modelo de integração contínua proposto pelo xp.
De acordo com esse modelo, os pares seguem um roteiro de oito passos:
- Assegurar que o projeto compila e todos os testes automatizados executam com sucesso
- Conquistar a vez de integrar
- Criar um backup do projeto na estação de trabalho
- Fazer update do projeto
- Assegurar que o software continua compilando e os testes executam com sucesso
- Fazer commit do projeto
- Apagar o diretório do projeto na estação de trabalho e fazer checkout
- Assegurar que o software continua compilando e que os testes executam com sucesso
Veremos adiante a explicação de cada passo, bem como a execução do roteiro manualmente.
1. Assegurar que o projeto compila e todos os testes automatizados executam com sucesso
Em xp, a equipe busca assegurar que o repositório esteja permanentemente consistente. Isso significa que, a qualquer momento, se um par fizer checkout do projeto, o código deve ser capaz de compilar perfeitamente, bem como passar em todos os testes. Para que esse objetivo seja alcançado, o par que estiver integrando deve ter o cuidado de assegurar que aquilo que for para o repositório compile e passe nos testes.
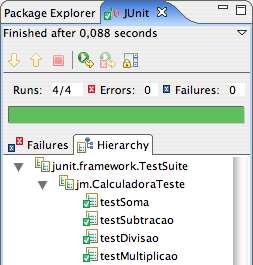
No caso do segundo par, Carlos e Denise, eles compilaram o código, executaram os testes e obtiveram um resultado positivo, conforme indicado na Figura 12.
Figura 12: Testes passam, permitindo que o código possa ser armazenado no repositório.
2. Conquistar a vez de integrar
É difícil manter o repositório consistente se os pares puderem fazer commit (gravar suas alterações no repositório) sempre que quiserem, inclusive enquanto outros pares também estiverem fazendo o mesmo. Obtém-se melhor controle sobre o processo quando apenas um par pode integrar de cada vez. Nesse cenário, que é o utilizado em projetos xp, quando um par estiver integrando, todos os demais devem aguardar a vez.
Isso pode se tornar um problema se cada integração consumir muito tempo. Mas, esse normalmente não é o caso em xp, porque os pares integram diversas vezes por dia, o que torna cada integração relativamente rápida (por haver pouco a ser integrado de cada vez).
É necessário garantir que apenas um par integre de cada vez. Isso pode ser conseguido de inúmeras formas. Por exemplo, a equipe pode separar um computador para ser usado exclusivamente com o propósito de integrar. Assim, o par que quiser integrar deve copiar o workspace para esse computador, ir até ele, executar o roteiro de integração e voltar para sua estação de trabalho quando tiver terminado. Mais adiante, trataremos de situações nas quais a equipe seja grande demais e não possa trabalhar junta em um mesmo ambiente, dificultando assim o uso de um computador exclusivo para integração.
Outra alternativa consiste em adotar um sinalizador, que é um instrumento visual cuja posse determina quem pode integrar no momento. O sinalizador pode ser qualquer coisa que indique claramente que uma integração está ocorrendo. Por exemplo, um de nossos clientes, a Ancar, utiliza um boneco de borracha do Bob Esponja! Quando um par deseja integrar, deve obter o boneco, pressioná-lo duas vezes (fazendo um barulho que indica o início da integração) e, em seguida, colocá-lo sobre o monitor. Quando a integração termina, o par pressiona o boneco uma vez, indicando que a integração terminou, e o coloca em outro lugar (ou simplesmente o repassa para o próximo par que quiser integrar). Veja o Bob Esponja em ação na Figura 13.
Figura 13: Bob Esponja usado como sinalizador para indicar quem conquistou a vez de integrar.

3. Criar um backup do projeto na estação de trabalho
Por maiores que sejam os esforços para tornar o processo de integração seguro, problemas podem ocorrer e o risco de se perder o trabalho produzido está presente. No passo a seguir teremos que fazer um update do projeto, para que alterações feitas no repositório sejam trazidas para a estação de trabalho do desenvolvedor. Na maioria das vezes essas alterações convivem bem com o que o desenvolvedor está produzindo. Mas de tempos em tempos elas podem entrar em conflito com o trabalho que acabou de ser feito; por exemplo, quando após um update não se consegue mais compilar o projeto e não há uma solução fácil.
Para que o desenvolvedor possa ter acesso ao código que havia escrito antes de efetuar o update, caso necessite, é recomendável que se faça uma cópia de segurança do diretório contendo o projeto antes de executar o update.
4. Fazer update do projeto
Antes de gravar alterações no repositório, temos que integrá-las na máquina reservada para integrações. Para isso, executamos um update. Trata-se de um comando do CVS que traz para nossa estação tudo aquilo que foi alterado no repositório desde a última vez que foi executado um checkout.
O Eclipse ajuda a realizar o update de forma simples. Para ver como o processo funciona, mude para o Eclipse que está simulando o par Carlos e Denise. Agora, peça para sincronizar com o repositório clicando com o botão direito na raiz do projeto e escolhendo a opção Team>Synchronize with Repository. Você deverá ver o conteúdo da Figura 14.
Figura 14: Sincronizando o projeto no workspace do segundo par.
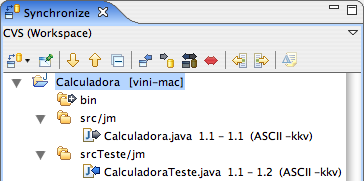
Note que a classe CalculadoraTeste é mostrada com uma seta para a esquerda. Isso indica que a versão do repositório está mais nova que a versão na estação de trabalho. Portanto, é necessário substituir a versão local, pela versão no CVS. Clique sobre essa classe com o botão direito e escolha a opção Update, como mostrado na Figura 15.
Figura 15: Fazendo update da classe CalculadoraTeste.
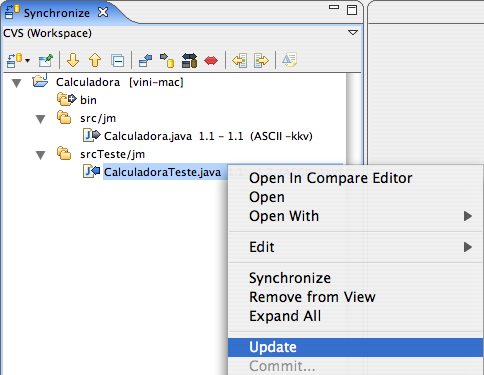
Agora que já temos todas as novidades do repositório, podemos prosseguir. Mas antes, podemos aproveitar para resolver um pequeno detalhe. Veja novamente a Figura 15. Repare no diretório bin. O Eclipse nos informa, através de uma seta apontando para a direita contendo um sinal de adição, que ele precisa ser adicionado ao CVS. Entretanto, esse diretório armazena o código compilado de nossa aplicação, que normalmente não precisa ser armazenado no repositório. Podemos configurar o CVS para ignorar todo o conteúdo desse diretório, de modo que não seja mais mostrado durante o processo de sincronização. Para tanto, clique sobre ele com o botão direito e escolha a opção Add to .cvignore.
5. Assegurar que o software continua compilando e que os testes executam com sucesso
Quando integramos o código local com alterações trazidas do CVS há sempre o risco de que as novidades façam nosso código deixar de compilar, os testes deixarem de passar, ou ambos. Sendo assim, precisamos recompilar a aplicação, executar os testes e corrigir eventuais erros antes de prosseguir. Vamos supor nesse caso que Carlos e Denise compilem o projeto e executam os testes, e tudo continue funcionando. Portanto, eles podem gravar suas alterações no passo seguinte.
6. Fazer commit
Para fazer um commit (armazenar suas alterações no repositório), basta clicar com o botão direito sobre a raiz do projeto e escolher a opção Commit.
7. Apagar o diretório do projeto na estação de trabalho e fazer checkout
Como explicado anteriormente, buscamos assegurar que qualquer par de desenvolvedores seja capaz de fazer checkout do projeto a qualquer momento, com a segurança de que o software possa ser compilado e os testes possam funcionar imediatamente. Por essa razão, antes de considerar a integração terminada, o par que está integrando deve apagar o diretório de trabalho da máquina de integração (o que não deve gerar maiores preocupações, pois um backup foi feito no segundo passo), e depois fazer checkout do projeto nessa mesma máquina. Para apagar o projeto, use o procedimento normal do Eclipse (botão direito e Delete).
Após apagar, deve-se fazer o checkout. Na perspectiva CVS Repositories expanda a linha correspondente ao repositório no qual se encontra o projeto. Clique com o botão direito sobre o projeto e escolha a opção Check Out As. Depois escolha Check out as project in the workspace.
8. Assegurar que o software continue compilando e os testes executam com sucesso
Finalmente, se tudo tiver corrido bem, o código irá compilar e os testes irão passar. Nesse momento, a integração terá terminado com sucesso e a máquina de integração (ou sinalizador) poderá ser liberada para outro par.
Possíveis problemas
O cenário descrito anteriormente representa o melhor caso, quando tudo corre bem. Mas nem sempre as coisas funcionam de primeira. Vários problemas podem ocorrer durante a integração, e é útil conhecer os principais deles.
Na integração descrita anteriormente, Carlos e Denise editaram a classe Calculadora. Suponha que ao mesmo tempo, Ana e Bruno também tivessem editado a mesma classe com o objetivo de incluir o método raizQuadrada(), conforme a Listagem 4.
Listagem 4: Ana e Bruno adicionam o método raizQuadrada() à classe Calculadora.
package jm;
public class Calculadora {
public int soma(int valor, int outroValor) {
return valor + outroValor;
}
public int subtrai(int valor, int outroValor) {
return valor - outroValor;
}
public int divide(int valor, int outroValor) {
return valor / outroValor;
}
public int multiplica(int valor, int outroValor) {
return valor * outroValor;
}
public double raizQuadrada(double numero) {
return Math.sqrt(numero);
}
}
Note na listagem que, além do novo método, o código ainda contém a versão antiga dos parâmetros. Portanto, já está diferente do que se encontra no CVS. Ao fazer a integração, Ana e Bruno enfrentarão um conflito, isto é, uma ou mais linhas de código foram editadas ao mesmo tempo por mais de um par e portanto o CVS não sabe como conciliar as contribuições de cada um. Quando isso acontece, o par que está integrando é responsável por conciliar as modificações manualmente. (É importante salientar que no xp os pares têm total autonomia para integrar sempre que alcançarem um ponto no desenvolvimento em que considerem apropriado fazê-lo.)
Na Figura 16, você observa o que o Eclipse informou quando Ana e Bruno sincronizaram o projeto. Os símbolos vermelhos indicam a existência de conflitos. Clicando-se duas vezes sobre o arquivo, o Eclipse mostra a tela da Figura 17.
Figura 16: Sincronização revela a existência de conflitos na classe Calculadora.
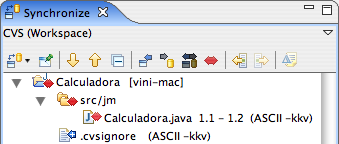
Figura 17: Eclipse revela as diferenças entre o código local e o armazenado no CVS.
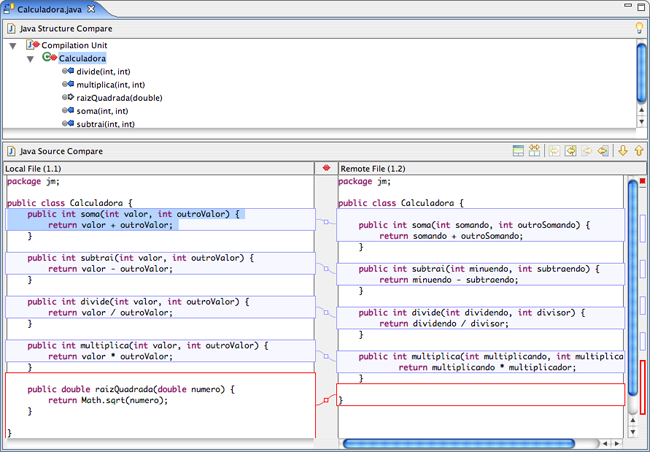
As áreas de código marcadas em azul claro indicam alterações armazenadas no repositório que podem ser trazidas para a estação de trabalho local com segurança, pois não conflitam com nada que tenha sido editado localmente. A área marcada em vermelho delimita um trecho do arquivo cujo conteúdo entra em conflito com uma alteração efetuada no repositório.
Para solucionar essa questão, começaremos trazendo do CVS todas as mudanças que não geram conflito. Para isso, basta clicar no ícone indicado na Figura 18. O resultado dessa ação é apresentado na Figura 19.
Figura 18: Clicando-se no ícone enfatizado em vermelho o CVS traz todas as alterações não-conflitantes.

Figura 19: Eclipse conciliou automaticamente as alterações não-conflitantes.
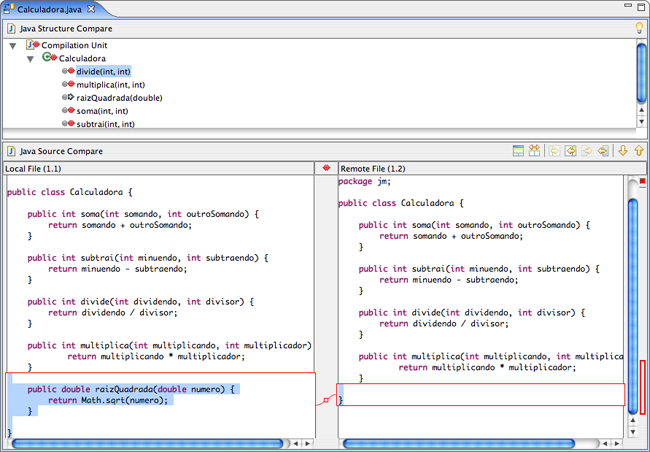
Apesar de o Eclipse ainda acusar um conflito, analisando a classe notamos que o código já está correto. Ele apenas acusou o conflito devido a uma sobreposição de edições em linhas idênticas, tanto no código que está no workspace, quanto no que está no repositório. Precisamos apenas informar ao Eclipse que o código que temos agora já está integrado, de modo que possamos fazer o commit do mesmo. Para isso, basta clicar com o botão direito sobre a classe Calculadora e escolher a opção Mark as Merged. Finalmente podemos fazer o commit do projeto clicando com o botão direito sobre a raiz do projeto e escolhendo Commit.
Automatizando a integração
É importante que o processo de integração seja automatizado para assegurar que os passos não sejam esquecidos e também garantir maior velocidade. Para automação pode-se utilizar, por exemplo, o script do Ant mostrado na Listagem 5 que deve ser armazenado em um arquivo chamado build.xml na raiz do projeto. Faça o commit desse arquivo e, em seguida, selecione a opção de menu Window|Show View>Ant. Arraste o arquivo build.xml e o solte nessa view. Você deverá ver a Figura 20. Para executar o script do Ant, clique com o botão direito do mouse sobre a raiz da view Ant e selecione a opção de menu Run As>Ant Build como ilustrado na Figura 21.
Listagem 5: build.xml - Script do Ant para automatizar a integração.
<project name="Calculadora" basedir=".." default="integrate">
<property name="project.dir" value="${ant.project.name}"/>
<property name="backup.dir" value="Backup${project.dir}"/>
<property name="src.dir" value="${project.dir}/src"/>
<property name="srcTeste.dir" value="${project.dir}/srcTeste"/>
<property name="build.dir" value="${project.dir}/bin"/>
<property name="lib.dir" value="${project.dir}/lib"/>
<property name="allTests.class" value="jm.AllTests"/>
<property name="cvsroot" value=
":pserver:vinicius@vini-mac:/usr/local/cvs/desenvolvimento"/>
<path id="project.classpath">
<pathelement location="${build.dir}"/>
<fileset dir="${lib.dir}">
<include name="*.jar"/>
</fileset>
</path>
<taskdef name="junit"
classname= "org.apache.tools.ant.taskdefs.optional.junit.JUnitTask">
<classpath refid="project.classpath"/>
</taskdef>
<target name="backup">
<delete dir="${backup.dir}"/>
<copy todir="${backup.dir}">
<fileset dir="${project.dir}" defaultexcludes="false" />
</copy>
</target>
<target name="update">
<cvs cvsroot="${cvsroot}" command="update -d ${ant.project.name}"
failonerror="true"/>
</target>
<target name="build">
<mkdir dir="${build.dir}"/>
<javac debug="on" srcdir="${src.dir}" destdir="${build.dir}"
failonerror="true">
<classpath refid="project.classpath"/>
</javac>
<javac debug="on" srcdir="${srcTeste.dir}" destdir="${build.dir}"
failonerror="true">
<classpath refid="project.classpath"/>
</javac>
</target>
<target name="test" depends="build">
<dirname file="build.xml" property="current.dir"/>
<junit haltonfailure="true" haltonerror="true" fork="true"
dir="${current.dir}">
<classpath>
<path refid="project.classpath"/>
</classpath>
<formatter type="plain" usefile="false"/>
<test name="${allTests.class}"/>
</junit>
</target>
<target name="commit">
<cvs cvsroot="${cvsroot}" command="commit -m '' ${ant.project.name}"
failonerror="true"/>
</target>
<target name="checkout">
<delete dir="${project.dir}"/>
<cvs cvsroot="${cvsroot}" command="checkout -P ${ant.project.name}" />
</target>
<target name="integrate" depends="test, backup, update, test, commit,
checkout">
<antcall target="test"/>
<echo message="Integracao concluida com sucesso."/>
</target>
</project>
Figura 20: View do Ant mostrando targets presentes no build.xml.
Figura 21: Executando o script do Ant.
Selecione a aba Classpath, e clique no botão Add JARs conforme a Figura 22 e escolha junit.jar (dentro do diretório lib). Finalmente, clique no botão Run. Quando tratamos do junit.jar pela primeira vez, nosso objetivo foi configurar o Eclipse para reconhecê-lo, viabilizando assim a implementação do teste. O Ant, por sua vez, é uma ferramenta à parte, que também precisa ter acesso ao junit.jar para que possa executar tarefas associadas ao JUnit. Isso explica por que temos que fazer esse último passo antes de executar o script do Ant.
Figura 22: Configurando o classpath do Ant.
Modelos de Integração Contínua
Existem duas formas de executar a integração contínua: síncrona e assíncrona.
Integração Contínua Síncrona
Esse artigo está demonstrando a integração contínua síncrona, onde apenas um par integra seu trabalho de cada vez e outros pares só são liberados para integrar ao serem informados do término da integração corrente. Mas não são todos os projetos que podem usar esse modelo de integração, pois ele exige que os desenvolvedores trabalhem juntos, normalmente em uma mesma sala. Desse modo se pode garantir que apenas um par integre de cada vez, utilizando-se um computador dedicado à integração, por exemplo.
Além disso, para usar a forma automatizada de integração é essencial a existência de testes automatizados, para garantir que tudo está funcionando antes de efetuar os commits. Se você analisar atentamente o script build.xml fornecido, notará que qualquer falha de compilação ou de merge, ou falhas nos testes automatizados, fará o script do Ant ser interrompido antes que as alterações possam ser gravadas no repositório através do comando commit do CVS. Nas linhas abaixo, extraídas da Listagem 5, as diretivas que fazem o script ser interrompido automaticamente em caso de erro estão marcadas em negrito.
(...)
<cvs cvsroot="${cvsroot}" command="update -d ${ant.project.name}" failonerror="true"/>
(...)
<javac debug="on" srcdir="${src.dir}" destdir="${build.dir}" failonerror="true">
(...)
<javac debug="on" srcdir="${srcTeste.dir}" destdir="${build.dir}" failonerror="true">
(...)
<junit haltonfailure="true" haltonerror="true" fork="true" dir="${current.dir}">
(...)
<cvs cvsroot="${cvsroot}" command="commit -m '' ${ant.project.name}" failonerror="true"/>
(...)
Esse modelo de integração procura garantir a maior proteção possível para o repositório, fazendo com que apenas arquivos consistentes (capazes de compilar e passar nos testes) sejam armazenados. Esse modelo também força os desenvolvedores a atuarem imediatamente quando acontecem falhas durante a integração. Desse modo, evita-se que os problemas só sejam detectados e corrigidos tardiamente.
Integração contínua assíncrona
Projetos nos quais os desenvolvedores não trabalhem juntos em uma mesma sala, como por exemplo a maioria dos projetos open source, não comportam a utilização do modelo de integração síncrona, pois em tais casos torna-se difícil ou impossível garantir que apenas um desenvolvedor irá integrar de cada vez. Nessas situações, o modelo assíncrono de integração contínua é mais apropriado.
Nesse modelo, o desenvolvedor integra seu código, executando um subconjunto dos passos descritos anteriormente:
- Assegurar que o projeto compila e todos os testes automatizados executam com sucesso
- Criar um backup do projeto na estação de trabalho
- Fazer update do projeto
- Assegurar que o software continua compilando e os testes executam com sucesso
- Fazer commit do projeto
Depois disso, uma ferramenta de apoio à integração contínua assíncrona, como o CruiseControl, monitora o repositório permanentemente. Sempre que detecta mudanças (porque alguém fez um commit), o CruiseControl faz checkout de todo o projeto automaticamente, compila o projeto e executa todos os testes. Quando ocorre algum erro de compilação, de merge ou na execução dos testes, a ferramenta envia um e-mail para o desenvolvedor responsável pelo problema. O desenvolvedor, por sua vez, deve fazer as correções o mais brevemente possível e colocá-las no repositório.
A integração contínua assíncrona permite o trabalho de desenvolvedores distribuídos geograficamente, porém é um pouco mais arriscada e menos eficiente que a integração síncrona. O risco aumenta porque o repositório pode ficar inconsistente durante alguns períodos de tempo – sempre que um erro ocorre e o responsável por ele ainda não fez o commit das correções.
Um dos valores básicos do xp é feedback: busca-se obter feedback rápido e freqüente sobre tudo que é produzido. A integração contínua é uma forma de obter feedback sobre nosso código, indicando se ele consegue conviver em harmonia com o restante do código no repositório.
Na integração assíncrona, a eficiência diminui porque leva mais tempo para o desenvolvedor descobrir que cometeu um erro. É comum o desenvolvedor receber a notificação de um erro depois de já ter iniciado uma nova atividade. Ao ser notificado, deve parar a nova tarefa, relembrar o que havia feito na tarefa anteriormente e corrigir o erro.
O processo síncrono é mais eficiente no uso do feedback exatamente porque impede o desenvolvedor de desviar sua atenção para qualquer outra atividade, enquanto a integração não tiver sido concluída com sucesso.
Identificação dos desenvolvedores
Equipes XP, em que todos os desenvolvedores trabalham em pares, em uma mesma sala, costumam utilizar um único login para toda a equipe acessar o CVS. Isso torna impossível determinar através dos logs do CVS quem fez determinada alteração. Existem algumas razões para se agir dessa forma.
Em xp a responsabilidade por implementar uma funcionalidade é sempre atribuída a no mínimo duas pessoas. Na maioria dos casos, diversas pessoas da equipe trabalham juntas, revezando-se em pares, para implementar as histórias (como as funcionalidades são chamadas em xp). Por isso costuma-se usar um login genérico, compartilhado por todos os pares.
A integração contínua síncrona, tal como apresentada aqui, leva em conta essa questão. O script do Ant apresentado usa um único login para o CVS, sem a possibilidade de alterá-lo.
Já quando uma equipe trabalha com integração assíncrona, o problema se inverte completamente. Nesse caso a identificação torna-se importante, já que (por exemplo) é desejável a possibilidade de enviar relatórios de erros para os desenvolvedores responsáveis pelos mesmos. Assim, na integração assíncrona, é necessário que se use o login específico de cada desenvolvedor que estiver acessando o CVS.
Comentários nos commits
O CVS permite que o desenvolvedor adicione um comentário cada vez que faz o commit de um arquivo. Assim ele pode, por exemplo, resumir as alterações realizadas e, sobretudo, explicar porque elas foram feitas. Tais comentários serão úteis para outros desenvolvedores ao acessarem o histórico de determinado arquivo.
Para acessar esse histórico no Eclipse, por exemplo, clique na classe Calculadora com o botão direito e escolha a opção Team>Show Resource History. O resultado é mostrado na Figura 23.
Figura 23: Histórico de alterações da classe Calculadora.

Em equipes xp, em que os desenvolvedores revezam-se entre pares, o conhecimento sobre o projeto é disseminado de forma mais rica. Por essa razão, muitas dessas equipes consideram desnecessário armazenar comentários no CVS. Nesse artigo, estamos considerando uma equipe com essas características, na medida em que o script Ant apresentado faz o commit forçando os comentários a serem vazios, conforme se pode observar no trecho abaixo, extraído desse script:
<target name="commit">
<cvs cvsroot="${cvsroot}" command="commit -m ''
${ant.project.name}" failonerror="true"/>
</target>
O parâmetro –m '' é usado para armazenar um comentário vazio. Em uma equipe na qual se deseje possibilitar a inclusão de comentários e ainda assim usar a automação do Ant, é possível alterar o script para que ele solicite o comentário antes de efetuar o commit. Isso é particularmente importante quando se usa o modelo assíncrono de integração contínua. Nesse caso, os desenvolvedores normalmente trabalham em separado e é recomendável adicionar comentários durante os commits. Para isso, basta alterar o target do Ant que faz o commit, como a seguir:
<target name="commit">
<input addproperty="comentario"
message="Comentários para o commit"/>
<cvs cvsroot="${cvsroot}" command= "commit -m '${comentario}'
${ant.project.name}" failonerror="true"/>
</target>
Assim, ao executar o do Ant que, o Eclipse irá interromper a execução logo antes de efetuar o commit e solicitará um comentário, como ilustrado na Figura 24.
Em equipes XP, em que os desenvolvedores revezam-se entre pares, o conhecimento sobre o projeto é disseminado de forma mais rica. Por essa razão, muitas dessas equipes consideram desnecessário armazenar comentários no CVS. Nesse artigo, estamos considerando uma equipe com essas características, na medida em que o script Ant apresentado faz o commit forçando os comentários a serem vazios, conforme se pode observar no trecho abaixo, extraído desse script:
Freqüência de integração
Quando um desenvolvedor integra várias vezes ao dia, eventuais erros de integração são detectados mais rapidamente, pois obtém-se feedback sobre o que está sendo integrado várias vezes ao dia. Feedback rápido e menos código produzido significam a possibilidade de solucionar problemas de integração com maior rapidez, mesmo quando uma equipe não usa comentários nos commits.
Por exemplo, o CVS permite fazer comparações entre versões de um arquivo, possibilitando verificar diferenças entre uma versão e outra. Para acionar esse recurso, clique com o botão direito sobre um arquivo e escolha a opção Compare With>Revision.
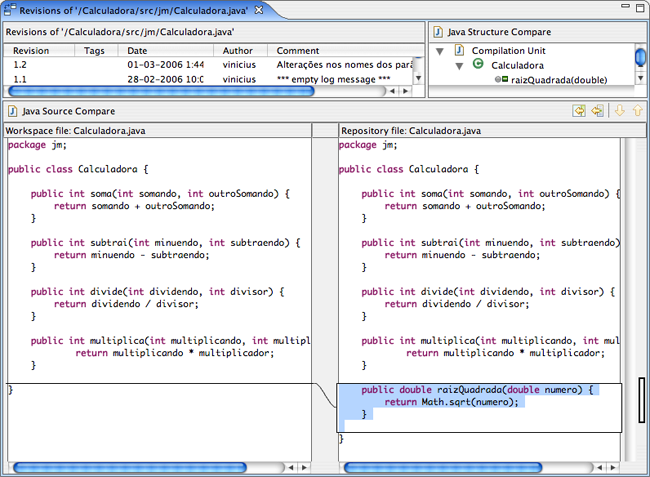
A Figura 25 mostra a comparação de duas versões da classe Calculadora. É fácil ver a diferença entre elas: o método raizQuadrada(). Note que nesse caso, como a alteração foi pequena ficou fácil compreender a diferença entre as versões. Integrações freqüentes ajudam a assegurar que as alterações sejam pequenas entre uma versão e outra do arquivo, o que ajuda a compreender a evolução dos arquivos e torna eventuais depurações mais fáceis, mesmo quando comentários não são adicionados durante os commits.
Figura 25: Comparação entre versões diferentes da classe Calculadora.
Conclusões
Em um projeto onde vários desenvolvedores trabalham juntos, é necessário estabelecer um processo seguro para a integração das contribuições de cada desenvolvedor. Em xp, utiliza-se a prática de integração contínua, na qual os desenvolvedores integram o que produzem com o repositório diversas vezes ao dia. Isso é feito de forma segura, seguindo-se um roteiro que é automatizado. A integração busca assegurar que o repositório permaneça sempre consistente, possibilitando que qualquer desenvolvedor possa obter todo o código do projeto, a qualquer momento, sendo então capaz de compilá-lo e executar todos os testes com sucesso.
Baixe os arquivos desse tutorial.
Autoria
Texto de Vinícius Manhães Teles.
Ilustrações de Leandro Mello.
Publicado em 10/10/2006.
Licenciado como Creative Commons Atribuição.
